You've probably felt it. A low hum of unease when AI hands you something that sounds right, even brilliant. But is it right?
It's a modern kind of angst, fed by a steady stream of "AI Got It Wrong" stories and reinforced by our own run-ins with confidently-wrong answers from AI tools. I used to sign my emails with the tagline "Often wrong, rarely in doubt." It was a friendly warning to colleagues to take my views with a dose of skepticism. Funny, coming from me. Not so funny when it's coming from a critical part of your operating system.
You're Right to Worry
Apple's ML researchers ran an experiment in late 2024. They called it GSM-Symbolic. They took every frontier AI model (GPT-o1, Claude, Llama, Gemini) and handed them grade-school math word problems. The models handled them fine. Then the researchers added one sentence to each problem. An irrelevant sentence. A single clause that didn't change the answer, didn't change the logic, didn't change anything a fourth-grader would need to track.
Accuracy dropped up to 65%.
Read that again. The smartest AI models in the world, the ones being embedded into your CRM, your analytics stack, your decision support tools, lost two-thirds of their math ability because someone added a sentence about a watermelon.
This isn't a story about AI being stupid. It's a story about AI being something other than what most people assume. LLMs don't reason the way we do. They pattern-match across enormous training data, and when the surface pattern gets perturbed, the reasoning collapses. The math didn't change. The problem stopped matching familiar patterns, and the pattern-matcher lost the thread.
Your angst is warranted. It's also likely pointed at the wrong things.
It's Not Just About Math
The Apple study is a canary. The same failure mode shows up anywhere a domain demands objective, verifiable correctness. Math. Legal citations. Factual claims about physical reality. Code logic. Financial calculations. Wherever there's a right answer and being confidently wrong has consequences, the LLM stops looking like a reasoner and starts looking like a very confident guesser.
The most famous example didn't happen in a lab. It happened in a federal courtroom.
In 2023, two New York attorneys filed a brief in Mata v. Avianca that cited six court decisions. Six cases that did not exist. ChatGPT had fabricated them. Invented quotes, invented judges, invented docket numbers. When opposing counsel couldn't find the cases and the court began asking questions, the lawyer asked ChatGPT whether the cases were real. ChatGPT said yes. The court sanctioned both attorneys. The story became a meme.
And then, over the following year and a half, it happened again. And again. And again. In state courts. In federal courts. In disciplinary hearings. By 2025, running databases of AI-hallucinated legal citations had logged dozens of confirmed cases. The lawyers weren't reckless. They weren't stupid. They trusted a tool that was confidently wrong, in a domain where being confidently wrong has consequences.
That is the angst in concrete form: I can't always tell when this thing is bluffing, and sometimes the stakes are high.
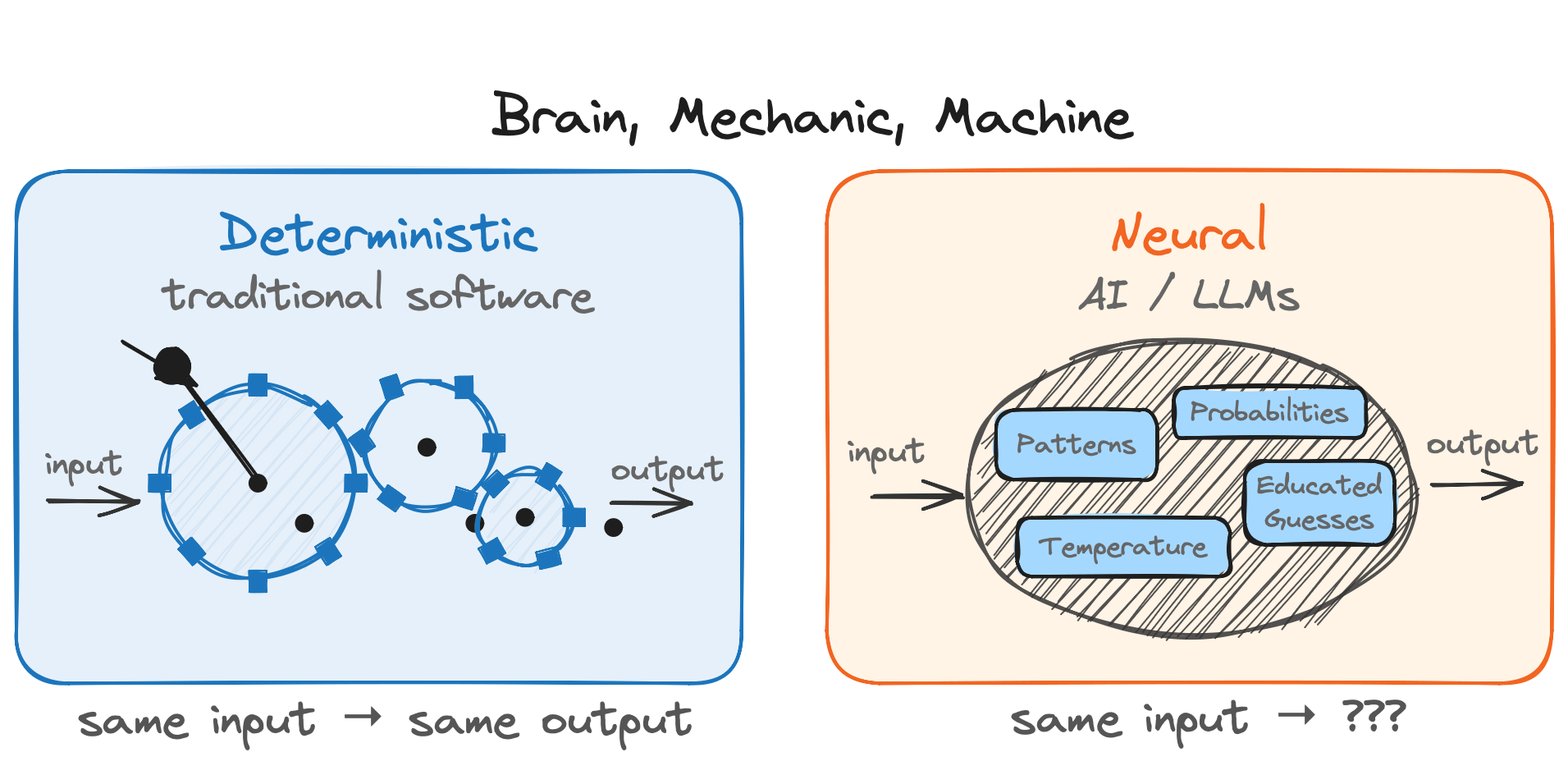
Brain, Mechanic, Machine
Traditional software is deterministic: a system of virtual cogs and wheels that reliably turns inputs into outputs. AI is the opposite. A black-box neural network trained on patterns, producing outputs no one can fully trace. Working with an AI system is more like working with a person than a machine.
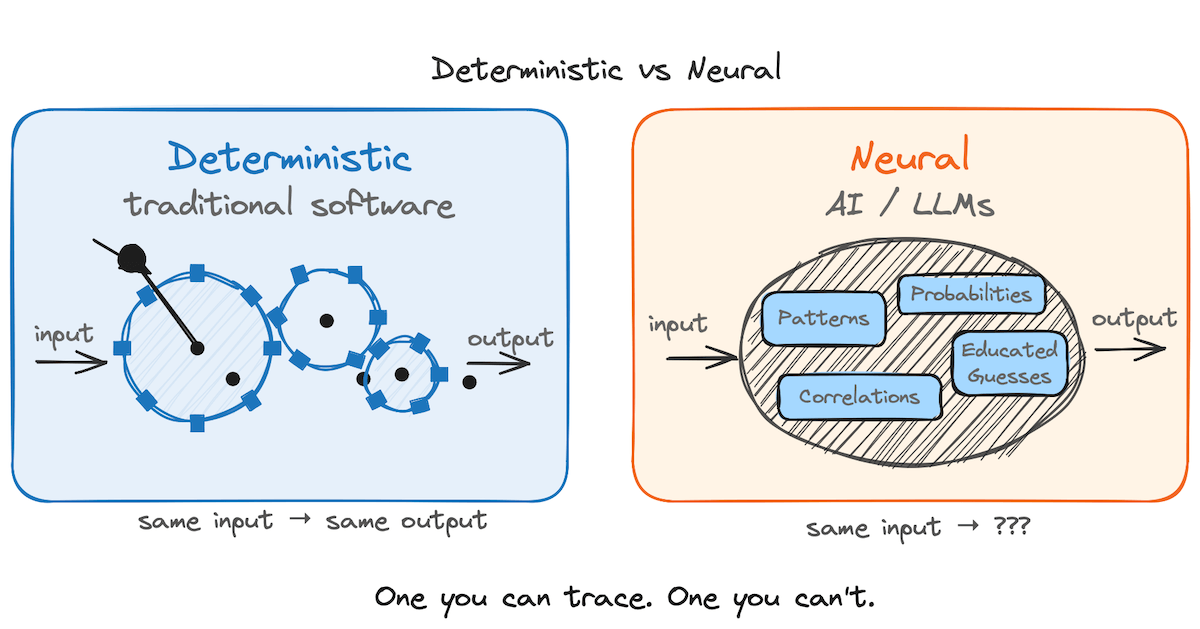
But modern AI agents aren't only brains. They're more like a brilliant mechanic who thinks, plans, and can then build deterministic machines to do much of the actual work. Claude doesn't just answer my questions. It often writes custom PHP, Python, and JavaScript, runs it, checks the results, and iterates. The creative judgment is neural. The execution is predictable code that runs the same way every time.
So an LLM is a terrible calculator. It's a very good builder of calculators. The pattern holds beyond math. Terrible fact-checker, fine builder of fact-checking pipelines. Terrible citation-verifier, decent builder of citation-verifying scripts. Mediocre self-auditor, competent builder of deterministic auditors that will check its work forever.
Stop asking the LLM to be the calculator. Start asking it to build the calculator.
A Real Example: This Blog
I run a two-person training firm, and Claude is embedded in nearly everything we do: client prep, program design, content creation, building our own tools. When Richard and I rebuilt our company website, we needed a blog system. Claude built the whole thing. A PHP engine that reads markdown files, parses metadata, renders HTML pages, handles URL routing, manages subscriber notifications, and automatically backs up every post with timestamps.
That blog engine contains zero AI. It's a PHP class with defined methods. It reads files from a directory. It sorts by date. It renders templates. Feed it the same blog post a thousand times and you'll get the same HTML a thousand times. There is no neural network involved in serving you this article. There is no probability of hallucination. It's a machine that Claude built.
Claude's contribution was understanding what I needed, making design decisions (flat files vs. database, markdown vs. rich text, how to handle drafts and backups), and writing clean, functional code. That design process was neural, and it was worth scrutinizing. I reviewed the architecture. I tested the output. I pushed back on decisions I disagreed with, the same way any manager would with a developer's proposed design.
Once the code was written and tested, the engine became a predictable system. My scrutiny shifted from did Claude make a good decision? to does the code work correctly? Two different questions, with two different risk profiles.
The Blend: Where the Angst Belongs
The most important category is the one where neural and mechanical fuse. Call it the blend. This is where the mechanic's judgment gets built into the machine.
Picture this. You ask an AI agent to identify your at-risk accounts. Claude decides "at-risk" means customers whose usage dropped more than 30% in the last quarter. It writes a script, pulls data from your CRM, and flags 847 accounts. The script runs perfectly every time. The code is solid. But the definition of at-risk was a neural judgment call. One moment of pattern-matching, now baked into a machine that will confidently execute it across your entire customer base. If Claude's interpretation doesn't match what your sales team means by "at-risk," you won't get a hallucination. You'll get a precisely wrong answer, delivered with mechanical confidence, across every account in your database.
Now remember what the Apple study showed. Neural reasoning is exactly the layer where a stray irrelevant detail can tip the output sideways. An extra sentence in the prompt. A subtle quirk in the data schema. A phrase in a CRM field that doesn't match the model's training distribution. Any of these can bend the judgment without anyone noticing, because the code it produces still looks clean and runs flawlessly.
That's where the danger lives: a reasonable-looking assumption, bent by noise at the neural layer, executing at scale inside a perfectly deterministic machine.
Hallucinations are loud. This is quiet. And it's where leaders need to put their scrutiny.
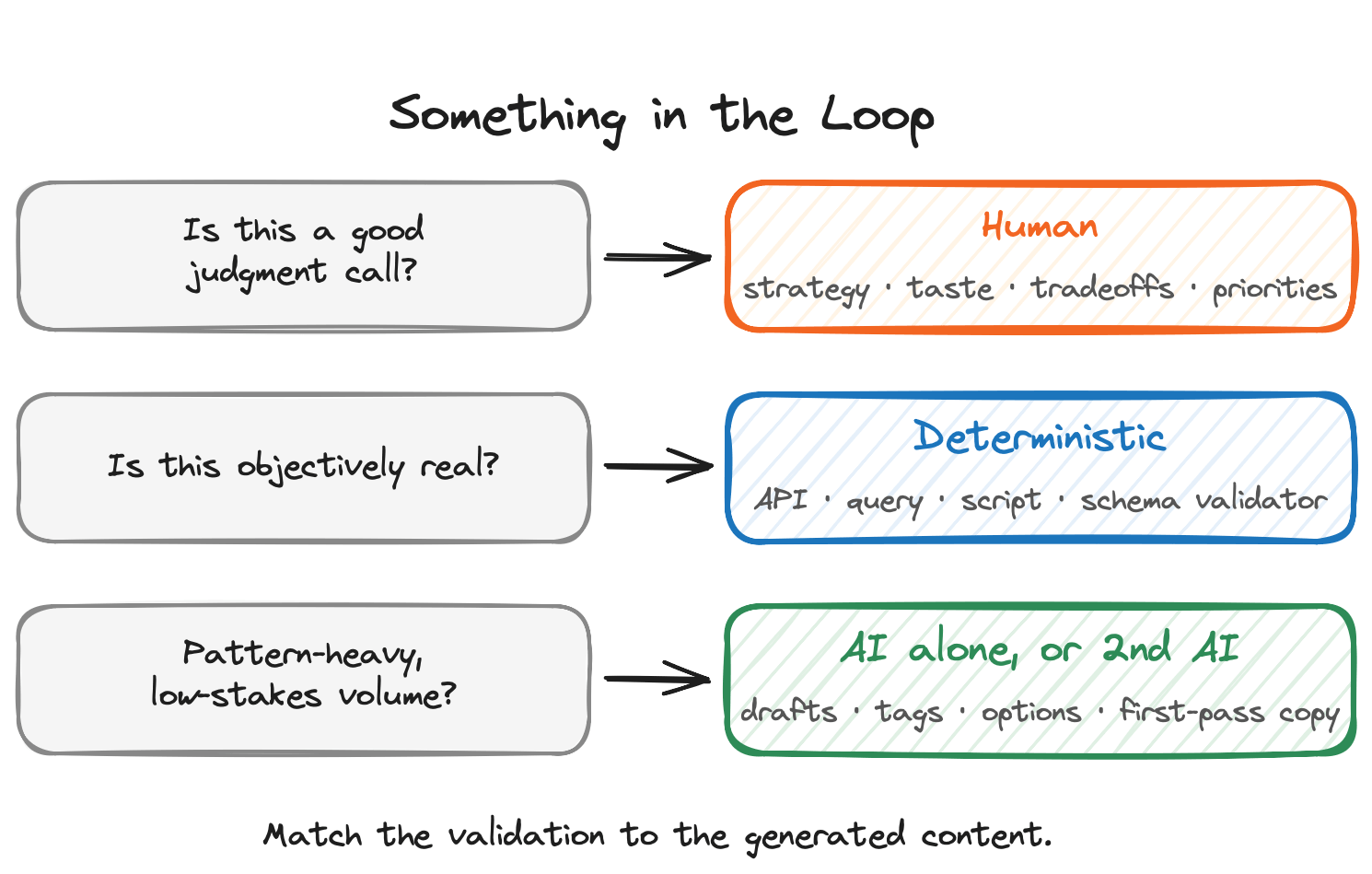
Something in the Loop
The industry's standard answer to AI risk is human in the loop. Keep a person at the controls. Have them review. Have them approve.
It's not wrong. It's insufficient.
Humans are slow, tired, and expensive. At scale, human-in-the-loop becomes a bottleneck or a rubber stamp. Nobody actually reads all 847 at-risk flags. And for certain kinds of checks, having a human do them is wasteful. If the question is "does this legal citation exist?" a human is slow and error-prone. A database query is fast and definitive. If the question is "does this row of numbers sum correctly?" a human with a calculator is a worse tool than the calculator alone.
The better framing isn't human-in-the-loop. It's something in the loop. And the right something depends on the question you need answered.
For judgment calls, the something is a human. Is this strategy sound? Does this message land? Is this the right tradeoff? That's the work humans are for.
For questions with a knowable, verifiable answer, the something is a deterministic system. Is this real? Does the math tie? Does this match the source of truth? Those questions have ground-truth answers somewhere, and software can get to them faster and more reliably than a person can. A query against an authoritative database. A script that runs the math. A schema validator. An API call to a source of record. Often a piece of code the AI itself can build.
For pattern-heavy, low-stakes volume work (rewording a draft, tagging content, surfacing options, generating first-pass copy), the AI alone is usually fine. The cost of being occasionally off is low. The upside of speed is high.
Back to the lawyers. Mata v. Avianca wasn't a failure of legal reasoning. It was a failure of verification. A tool existed that would have caught every fake citation before the brief was filed: Westlaw. A ten-line script could have pulled each cited case from the draft, queried Westlaw's API, and flagged any that didn't resolve to a real case. That validator didn't need a human. It didn't even need AI. It needed deterministic software pointed at a ground-truth source. A calculator (built by the AI, even) for the question is this real?
If that validator had been in the loop, the story would never have happened.
This is the move. Design AI workflows with the right something in the loop for the job at hand. The AI does the fast, creative, pattern-matching work it's good at: drafting the brief, proposing the definition, surfacing the options, writing the code. A deterministic system does the verification work it's good at: checking the math, validating the citations, querying the source of record, enforcing the schema. A human does what only humans can do: judgment, taste, strategy, relationship, priorities.
That's what an AI-literate workflow actually looks like. Not a person staring at every output. Not blind trust in every answer. A layered system where each kind of check is done by the tool that's best at it.
The Real Skill
When AI-produced work lands on your desk, ask three questions.
What am I looking at? Neural output (the AI thinking), mechanical output (code the AI built, now running), or blended output (a judgment call the AI made, executing as a machine)?
What kind of mistake is possible here? A neural mistake is a wrong fact or a bad synthesis. Loud and obvious once you spot it. A mechanical mistake is a bug. Consistent, findable, fixable once. A blended mistake is the quiet one: a reasonable-looking assumption, slightly wrong, executing at scale.
What belongs in the loop? Judgment calls need a human. Verifiable claims need a deterministic validator. Pattern-heavy volume work can often run on the AI alone. The skill is matching the check to the category.
The skill isn't trusting AI more or less. It's trusting it precisely. Know where to apply your judgment, where to let the machine do what machines do well, and where to wire in a deterministic check because the answer is knowable and the stakes are not.
What's Next
Our blog engine, the one with zero AI inside, is getting some AI features. A proofreading assistant. A headline suggester. Smart meta descriptions. Each involves the engine sending requests to an AI model, receiving neural output, and integrating it into the blog. A truly blended system. We'll document the build and share what we learn, including where we put deterministic validators in the loop and what happens when we don't.
The angst is real. You're right to worry. But the response isn't to use AI less. It's to design AI workflows with the right something in the loop for each part of the job.
The leaders who figure out how to tell those roles apart, and wire them together, will spend the next decade getting remarkable outcomes out of AI. Everyone else will spend it being very surprised.
Editor's note: Updated April 2026 to incorporate Apple's study on the limits of LLM reasoning, and the growing list of courtroom hallucinations.